[點晴CRM客戶管理系統]搜索引擎爬蟲工作原理-大揭秘
當前位置:點晴教程→點晴CRM客戶管理信息系統
→『 經驗分享&問題答疑 』
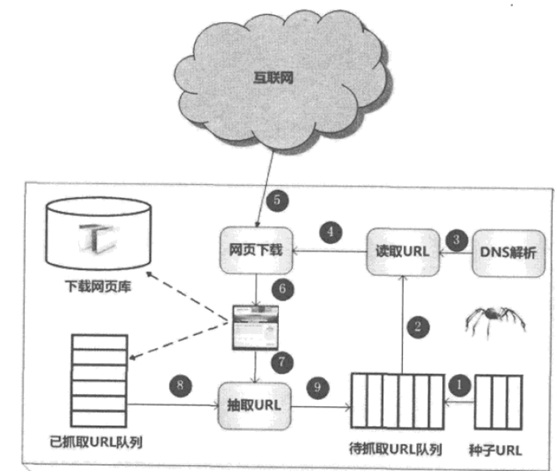
搜索引擎的處理對象是互聯網網頁,日前網頁數量以百億計,所以搜索引擎首先面臨的問題就是:如何能夠設計出高效的下載系統,以將如此海量的網頁數據傳送到本地,在本地形成互聯網網頁的鏡像備份。 網絡爬蟲即起此作用,它是搜索引擎系統中很關鍵也根基礎的構件。這里主要介紹與網絡爬蟲相關的技術,盡管爬蟲技術經過幾十年的發展,從整體框架上已相對成熟,但隨著聯網的不斷發展,也面臨著一些有挑戰性的新問題。 下圖所示是一個通用的爬蟲框架流程。首先從互聯網頁面中精心選擇一部分網頁,以這些網頁的鏈接地址作為種子URL,將這些種子URL放入待抓取URL隊列中,爬蟲從待抓取URL隊列依次讀取,并將URL通過DNS解析,把鏈接地址轉換為網站服務器對應的IP地址。 然后將其和網頁相對路徑名稱交給網頁下載器,網頁下載器負責頁面內容的下載。對于下載到本地的網頁,一方面將其存儲到頁面庫中,等待建立索引等后續處理;另一方面將下載網頁的URL放入已抓取URL隊列中,這個隊列記載了爬蟲系統已經下載過的網頁URL,以避免網頁的重復抓取。對于剛下載的網頁,從中抽取出所包含的所有鏈接信息,并在已抓取URL隊列中檢查,如果發現鏈接還沒有被抓取過,則將這個URL放入待抓取URL隊列末尾,在之后的抓取調度中會下載這個URL對應的網頁。如此這般,形成循環,直到待抓取URL隊列為審,這代表著爬蟲系統已將能夠抓取的網頁盡數抓完,此時完成了一輪完整的抓取過程。
對于爬蟲來說,往往還需要進行網頁去重及網頁反作弊。 上述是一個通用爬蟲的整體流程,如果從更加宏觀的角度考慮,處于動態抓取過程中的爬蟲和互聯網所有網頁之間的關系,可以大致像如圖2-2所身那樣,將互聯網頁面劃分為5個部分: 1.已下載網頁集合:爬蟲已經從互聯網下載到本地進行索引的網頁集合。 2.已過期網頁集合:由于網頁數最巨大,爬蟲完整抓取一輪需要較長時間,在抓取過程中,很多已經下載的網頁可能過期。之所以如此,是因為互聯網網頁處于不斷的動態變化過程中,所以易產生本地網頁內容和真實互聯網網頁不一致的情況。 3.待下載網頁集合:即處于上圖中待抓取URL隊列中的網頁,這些網頁即將被爬蟲下載。 4.可知網頁集合:這些網頁還沒有被爬蟲下載,也沒有出現在待抓取URL隊列中,不過通過已經抓取的網頁或者在待抓取URL隊列中的網頁,總足能夠通過鏈接關系發現它們,稍晚時候會被爬蟲抓取并索引。 5.不可知網頁集合:有些網頁對于爬蟲來說是無法抓取到的,這部分網頁構成了不可知網頁集合。事實上,這部分網頁所占的比例很高。 根據不同的應用,爬蟲系統在許多方面存在差異,大體而言,可以將爬蟲劃分為如下三種類型: 1. 批量型爬蟲(Batch Crawler):批量型爬蟲有比較明確的抓取范圍和目標,當爬蟲達到這個設定的目標后,即停止抓取過程。至于具體目標可能各異,也許是設定抓取一定數量的網頁即可,也許是設定抓取消耗的時間等。 2.增量型爬蟲(Incremental Crawler):增量型爬蟲與批量型爬蟲不同,會保持持續不斷的抓取,對于抓取到的網頁,要定期更新,因為互聯網的網頁處于不斷變化中,新增網頁、網頁被刪除或者網頁內容更改都很常見,而增量型爬蟲需要及時反映這種變化,所以處于持續不斷的抓取過程中,不是在抓取新網頁,就是在更新已有網頁。通用的商業搜索引擎爬蟲基本都屬此類。 3.垂直型爬蟲(Focused Crawter):垂直型爬蟲關注特定主題內容或者屬于特定行業的網頁,比如對于健康網站來說,只需要從互聯網頁而里找到與健康相關的頁面內容即可,其他行業的內容不在考慮范圍。垂直型爬蟲一個最大的特點和難點就是:如何識別網頁內容是否屬于指定行業或者主題。從節省系統資源的角度來說,不太可能把所有互聯網頁面下載下來之后再去篩選,這樣浪費資源就太過分了,往往需要爬蟲在抓取階段就能夠動態識別某個網址是否與主題相關,并盡量不去抓墩無關頁面,以達到節省資源的目的。垂直搜索網站或者垂直行業網站往往需要此種類型的爬蟲。 該文章在 2013/3/27 22:24:11 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886