字符集、編碼的前世今生
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
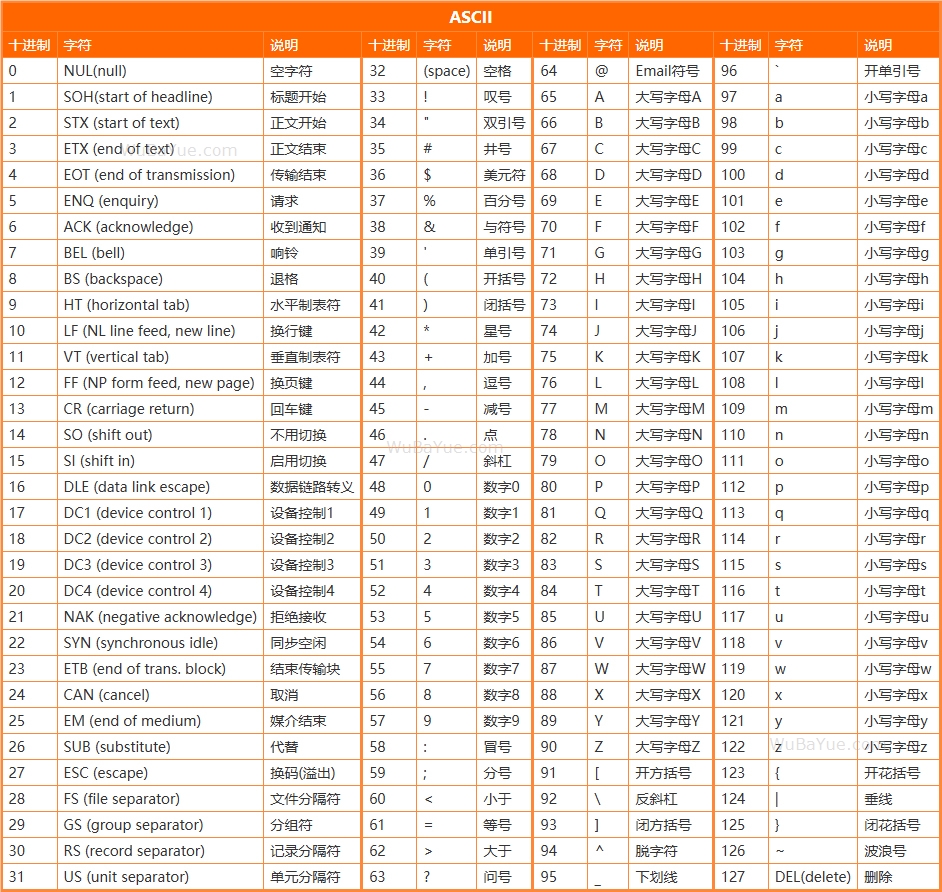
1 ASCII的誕生20世紀60年代的美國,計算機發展到集成電路階段,體積不斷縮小,功能不斷增強,應用軟件開始出現。但當時每個廠家都按自己的喜好來編碼,有的用6位表示一個字符,有的用7位表示一個字符,不同廠家之間有不同標準,軟件不能跨設備運行,兩個廠家生產出來的計算機無法交流。當時,編碼方式超過60種,僅IBM一家公司在自家不同的設備上就有9種不同的編碼。這時IBM里有位程序員意識到了這個問題,他認為所有廠家的編碼應該統一起來,并且從1960年開始干這個活,一年后他向ANSI(美國國家標準協會)提出統一計算機編碼的建議,ANSI覺得這個想法不錯,于是把各大廠商召集起來開會,利益紛爭的座談會一直開到1967年,ANSI實在受不了了,說算了你們別爭了,26個英文字母加10個數字加常用的書寫符號再加流行的打印控制湊齊128個,用7位存儲,前面32個用于控制,后面的用于顯示,128一二發,大吉大利,就這樣定了吧。 次年,美國總統林登·約翰遜下達紅頭文件,所有的計算機廠家必須遵循ANSI的標準。于是,大名鼎鼎的ASCII誕生。促成ASCII編碼的這位IBM員工的名字是:Bob Bemer(鮑勃·貝莫)
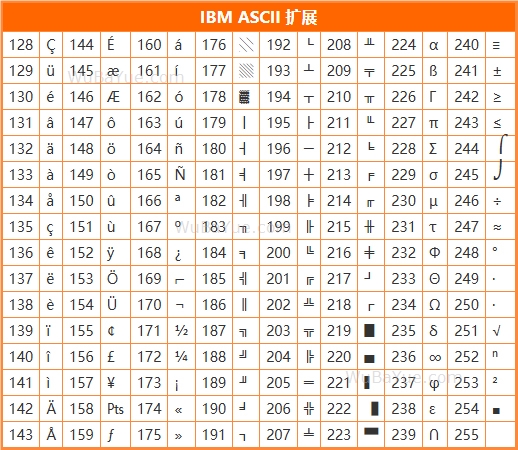
2 ASCII的自由擴展以后的若干年,ASCII在美國不溫不火,各廠家拿著紅頭文件照章辦事,直到1981年,一件石破天驚的事情讓世人重新重視和開始討論ASCII,這就是IBM個人電腦(PC)的誕生。PC完全顛覆了人們對計算機的印象,它成本低廉,體積小巧,很快就開始在全球蔓延。PC到了英國,英國人發現他們的英鎊符號£在萬能的PC里顯示不出來;PC到了希臘,希臘人發現讓他們引以為傲的希臘字母居然在PC里一個也敲不進去。IBM根據市場反饋,很快就決定把ANSI的7位ASCII標準擴展成8位,這樣就多出了一倍的字符。
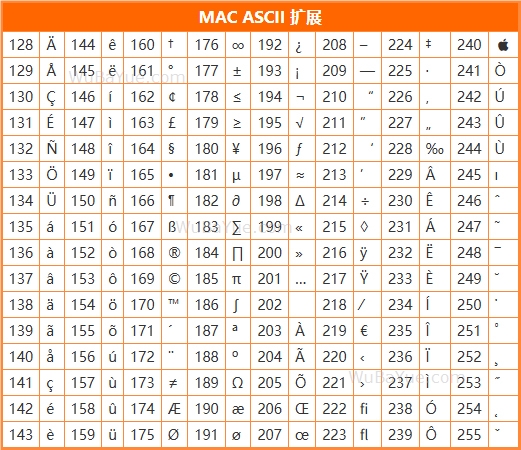
當時生產PC的可不止IBM一家,大多數人知道現在的iPhone、iPad稱霸全球,但很多人不知道早在1977年喬幫主的Apple II就在江湖上叱詫風云。同樣,喬幫主也毫不猶豫的把ANSI的7位擴展成了8位,還特意把240這個值設計成蘋果的標識。俗話說性格決定命運,也許喬幫主在擴展ASCII中畫下被啃掉一口蘋果的那天,就決定了30年后創造出的萬億美元市值公司。
3 GB2312
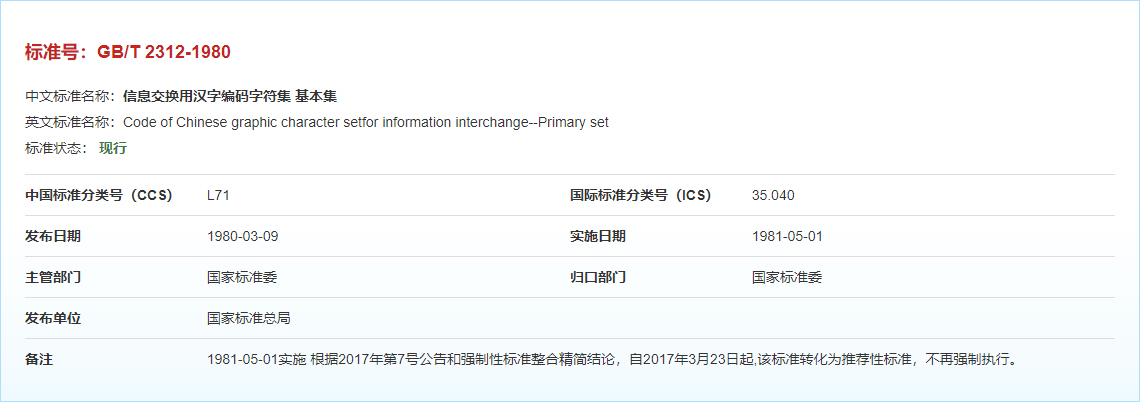
信息革命是繼蒸汽革命、電氣革命之后人類歷史上第三次科技革命,雖然信息革命發源于美國,但中國人民很早就意識到了信息革命的重要性。在IBM電腦興起的時候,我們召開完了十一界三中全會,聰明勤勞的中國人民敏銳的意識到漢字也需要信息化,但美帝規定的ASCII只有7位,即便擴展為8位,也容納不下博大精深的漢字,于是我們毫不猶豫的把一個字節擴展成兩個字節,考慮到兼容ASCII,將前面32個控制字符排除掉,高低位字節組合起來就有94X94=8836個,掐指一算,常用漢字夠了,順帶還可以將ASCII用兩個字節再重編碼一遍,于是便有了今天的全角半角字符之分。 1980年,中國國家標準總局制定了《信息交換用漢字編碼字符集》,1981年5月1日開始正式實施,標準號是:GB2312-80,選入了6763個漢字,分為兩級,一級字庫中有3755個,是常用漢字,二級字庫中有3008個,是次常用漢字;還選入了682個非漢字圖型字符,包含數字、一般符號、拉丁字母、日本假名、希臘字母、俄文字母、拼音符號、注音字母等。整個字符集分成94個區,每區有94個位。每個區位上只有一個字符,因此可用所在的區和位來對漢字進行編碼,稱為區位碼。1996年我們學校機房所有的486電腦上統一安裝的就是拼音、五筆和從來沒人會用的區位碼。 4 BIG5因為特殊歷史背景原因,GB2312在設計時并未考慮支持繁體中文,當時作為亞洲四小龍之一的臺灣省,經濟騰飛,計算機快速普及,但同樣,臺灣廠商各自采用不同的中文編碼方式,數據交互困難,臺灣人民的屏幕上亂碼滿天飛。于是在1983-1984年間,宏基(Acer)、神通(Mitac)、佳佳(KaoHSIN)、零一(Zero One)、大眾(FIC)五家商業公司共同制定了統一的繁體中文編碼標準,也許他們覺得自己應該是臺灣最大的五家公司,所以將這個編碼稱之為大五碼(BIG5)。BIG5采用雙字節編碼,收錄了常用與次常用繁體漢字13060個,以及日、俄、希臘字母、標點符號等共計1.9萬個字符,但遺憾的是BIG5不支持簡體中文,也不兼容GB2312,這樣在一個國家的兩個地區,使用著相同的語言文字,但計算機中存儲著兩種完全不同的編碼。 5 GBK時間來到九十年代,中國的改革開放在小平同志的帶領下初見成效,兩岸三地的經濟文化交流日益頻繁,普通家庭開始擁有個人電腦。同時,遠在大洋彼岸的比爾蓋茨正帶領著微軟緊鑼密鼓的開發著劃時代的操作系統Windows95,他們發現GB2312標準并不支持一些實際使用的漢字,比如常用于人名的“镕”、“喆”、“犇”、“垚”等,于是微軟開始在GB2312的基礎上進行擴展,除了增加GB2312標準中不支持的簡體字,還打包了BIG5中所有繁體字以及日韓語中使用的漢字共計21003個,將其命名為“國標擴展(Guo Biao Kuozhan)”,縮寫就是“GBK”。因為GBK并不是國家標準,只是微軟作為商業公司基于市場需求推出的編碼規范,所以這也為后來中文編碼的標準化埋下了隱患。 微軟作為一家美國公司,之所以能果斷快速的基于GB2312擴展出GBK,完全是借助了另一支強大力量,1993年,國際標準化組織(ISO)和國際電工委員會(IEC)聯合發布了ISO/IEC 10646-1,這是旨在統一全球編碼的一份國際標準,從西方的拉丁語、希臘語、斯拉夫語,到東方的日語、韓語、漢語,包括GB2312與BIG5中的字符,均在涵蓋范圍之內。同年,中國國家技術監督局采用了ISO/IEC 10646-1,頒布國標GB13000.1。所以微軟只是將GB2312與ISO/IEC 10646-1兩大標準進行了融合,它充當了國家標準向國際標準磨合過渡的潤滑劑,滿足那段特殊歷史時期的市場需求,GBK編碼也隨著Windows95迅速走進了中國的千家萬戶。 再來看一下使用粵語的香港和澳門地區,他們與臺灣一樣使用的是繁體字,所以字符編碼采用BIG5,但粵語中的一些特殊字符比如“邨”、“埗”、“涌”,在BIG5并未支持,于是香港政府不得不發布香港增補字符集(HKSCS,Hong Kong Supplementary Character Set)。 我們回顧一下當時的中文編碼情況,支持簡體中文的GB2312,支持繁體中文的BIG5,基于BIG5為粵語打的補丁HKSCS,計劃但尚未完成一統天下的ISO/IEC 10646,支持GB2312與BIG5中的字符但兩者編碼又不兼容的國標GB13000.1,兼容GB2312且支持BIG5中字符但不是國標的GBK,真是一個萬碼奔騰的時代! 6 Unicode的誕生在漫長的人類發展歷史中,有些人總能看穿時間,洞悉未來。比如來自蘋果和施樂公司的工程師Mark Davis、Lee Collins和Joe Becker,早在1987年就認為全世界所有文字符號終將融合,需要一份統一的編碼,他們于1988年發布了第一個試行標準Unicode 88,又于1991年推出了正式標準Unicode 1.0并成立Unicode聯盟。與Unicode有著相同偉大構想的還有另外兩家美國事業單位,也是上一章中曾經提到過的國際標準化組織(ISO)和國際電工委員會(IEC),他們計劃通過通用字符集(UCS,Universal Character Set)統一全世界的字符編碼并為此進行了多年的工作。幸運的是Unicode與ISO/IEC兩個項目組都意識到這個世界不需要兩種不兼容的字符集,自從他們知道了彼此的存在后便約定將協同工作,編碼完全相互兼容,并且以Unicode的名號昭告天下,因為這個名字更容易被記住。稍有遺憾的是說英語的美國人嚴重低估了這個世界其它語言的復雜性,早期的Unicode團隊認為16位支持的65536個字符足夠這個世界使用,但其實這個長度還不夠存放中國的象形文字,這些都不影響Unicode的偉大,只是在漫長的90年代,Unicode不溫不火,隱姓埋名,它在等待逆天改命的一個機會。 1999年,一款名為OICQ的即時通訊軟件火遍了中國大江南北,那年我上大一,成宿的跟異性網友在OICQ上聊天,現在的年青人無法理解,是因為他們無法體會從郵寄信件的筆友突然跨越到OICQ聊天的那種代差感;同時,新浪、網易、搜狐三大門戶已將傳統紙媒打折了腿下一步就該按在地上摩擦了;初代網絡游戲《石器時代》已開始改變玩家們對游戲的認知,而幫助陳天橋成為中國首富的《傳奇》也正在韓國發布上線。互聯網的驚濤駭浪正在席卷全球,所有國家的人們,都迫切的需要一個統一的字符集編碼,而Unicode,正是那個不二之選。從1991到1998的七年間,Unicode只迭代了4個版本,而從1998到1999的一年時間,Unicode就迭代了5個版本。 7 Unicode的規則很多人誤以為Unicode與GB2312、GBK、甚至UTF-8一樣,是一種具體的字符集編碼方式。其實Unicode并不是某種字符集編碼,而是一個標準化組織,負責制定一系列規則,基于這些規則,Unicode推出了三種具體的編碼:UTF-8、UTF-16、UTF-32。 規則1:Unicode字符編碼空間為U+0000至U+10FFFF碼點是為每個字符分配的唯一數字標識,在Unicode中以U+作為前綴,以16進制表示,比如字母“A”的Unicode碼點是U+0041(十進制為65),漢字“中”的碼點是U+4E2D(十進制為20013),碼點的取值范圍叫做編碼空間。 細心的你也許留意到了,Unicode編碼空間的起始U+0000與結束U+10FFFF,長度并不一樣。是的,大多數事物并非天生完美而是靠后天不斷完善的,Unicode最早計劃使用兩個字節16位支持65536個碼點,但遇到中國的象形文字后發現這個范圍明顯太小了,而好基友ISO計劃使用四個字節32位支持大約4億個碼點,又明顯太大了,于是雙方一合計,掐頭去尾21位支持一百多萬碼點,差不多剛剛好,于是編碼空間的上限便從U+FFFF(216)擴展到了U+10FFFF(221)。 Unicode編碼空間被均分為17份,稱為17個平面(Plane),編號0到16,每個平面包含為216即65536個碼點,平面又進一步劃分為塊(Block),不同平面不同塊中存儲著不同類型的Unicode字符集。 規則2:具有相同含義的字符是同一個字符Unicode規定了字符抽象原則,一個字符可能有多種形狀,但只要它們具有相同的含義,就認為是同一個字符,比如同一個漢字,行、楷、隸、草不同字體下的形狀各不相同,但Unicode認為它們是同一個漢字,分配唯一的碼點。 規則3:使用簡單字符組合出復雜字符Unicode還規定了動態組合原則,使用簡單的字符組合出復雜的字符,比如瑞典語字符?,就是由字母A和 ? 組合而成。 規則4:兼容以前的字符集編碼Unicode誕生于萬碼崩騰的年代,目標是統一市面上所有的字符集編碼,為了這個目標,Unicode聯盟在成立之初便制定了一項重要原則:雙向兼容所有現有字符集的編碼標準。所謂雙向兼容,就是當前任何字符集中的任何一個編碼都可以轉換為Unicode,并且可以再從Unicode轉換回原有字符集。因此,在Unicode中就存在一些“冗余”字符,比如拉丁字母“K”與熱力學單位“K”(開爾文)看起來完全一樣,但為了與之前一些字符集編碼的兼容,它們在Unicode中存在兩個不同的碼點,U+004B為拉丁字母K,名稱為“Latin Capital Letter K”,U+212A為熱力學單位K,名稱為“KELVIN SIGN”。Unicode中的每個碼點都有一個全局唯一的大寫名稱,https://www.unicode.org/Public/UNIDATA/NamesList.txt可以查看所有Unicode字符名稱。 8 UTF-8一統江湖Unicode聯盟根據自己制定的一系列規則,推出了三種具體的編碼方案:UTF-8、UTF-16、UTF-32。其中數字8、16、32稱之為碼元,表示在計算機中存儲Unicode字符的最小單元,比如UTF-8的碼元為8位,如果8位存不下一個字符就會擴展至8的整倍數16位,16位再存不下就會擴展至24位,而不允許使用9位或10位。UTF的含義是Unicode轉換格式(Unicode Translation Format),它負責將Unicode碼點以特定的碼元存儲在計算機中,所以UTF-8表示使用8位碼元存儲數據,UTF-16表示使用16位碼元存儲數據,UTF-32表示使用32位碼元存儲數據。 Unicode最早推出的是16位雙字節的定長編碼方案,但這個方案有一個致命缺陷,就是不兼容ASCII,我們知道ASCII是在1968年誕生的,而Unicode的推出時間已到了九十年代,這前后二十多年間,世界上產生了大量基于ASCII的文檔和軟件,要讓它們全部從8位ASCII遷移至16位Unicode,幾乎不可能。Unicode很快意識到這個問題,并馬上推出了兼容ASCII的方案:UTF-8,UTF-8也是目前使用最廣泛的編碼。
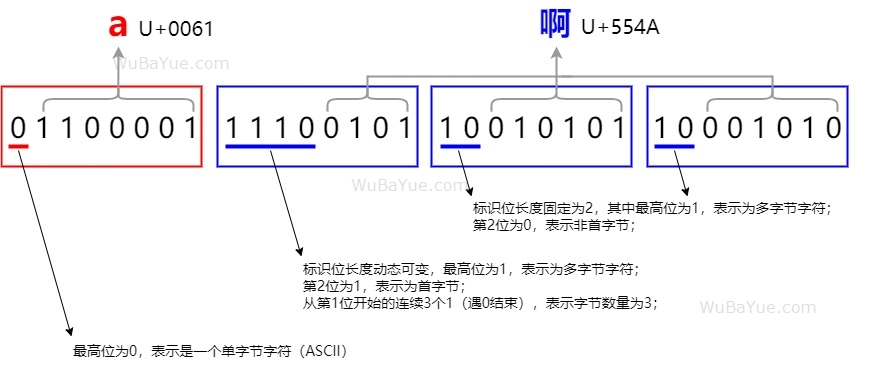
UTF-8是一個變長編碼方案,允許使用1-4個字節來存放一個Unicode字符,編碼邏輯如下: 首先判斷第一個字節的最高位,如果為0,表示這是一個單字節ASCII字符(此處不得不佩服ASCII編碼當初保留了最高位這個神英明神武的決定,否則后續的所有多字節編碼方案都難以兼容ASCII了)。 如果最高位為1,表示這是一個多字節Unicode字符,從第1位開始連續有n個1(遇0結束)代表著這個字符連續占用了n個字節,然后后續的這n個字節中,前兩位固定為標識符,后6位存放數據。
為便于理解,如上表格展示了UTF-8編碼中1個字節到4個字節字符的編碼示例,其中x表示數據位。因為UTF-8是目前使用最廣泛的編碼,基于兼容性考慮,在可預計的將來UTF-8也將具有長期統治地位,所以對于UTF-16與UTF-32本文就不作展開了。 轉自https://www.cnblogs.com/wubayue/p/18907899 該文章在 2025/6/5 15:36:40 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886