為何PostgreSQL沒(méi)有聚集索引?解讀兩大數(shù)據(jù)庫(kù)的設(shè)計(jì)差異
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
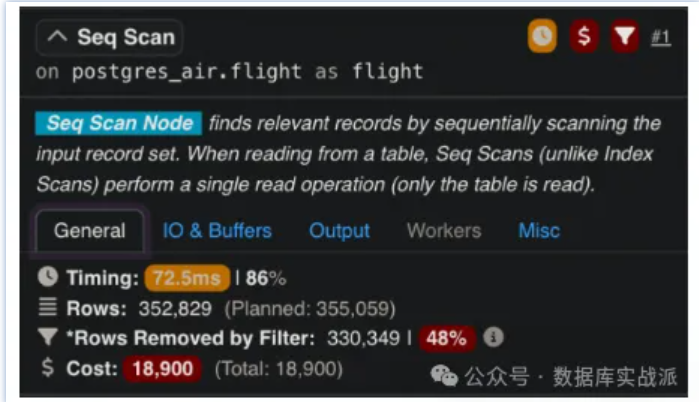
前言高效的數(shù)據(jù)檢索是數(shù)據(jù)庫(kù)管理的基石, PostgreSQL和SQL Server都能提供強(qiáng)大的數(shù)據(jù)訪(fǎng)問(wèn)方法以支持各種工作負(fù)載方面表現(xiàn)出色。然而,它們的實(shí)現(xiàn)方式存在顯著差異,反映了各自獨(dú)特的設(shè)計(jì)理念和使用場(chǎng)景。 在這篇文章中將介紹PostgreSQL提供的各種數(shù)據(jù)訪(fǎng)問(wèn)方法,其中包括一個(gè)非常獨(dú)特的特點(diǎn):PostgreSQL不支持聚集索引。這一根本性的差異對(duì)于理解PostgreSQL與SQL Server在數(shù)據(jù)存儲(chǔ)和檢索上的不同方式至關(guān)重要。 順序掃描任何數(shù)據(jù)庫(kù)系統(tǒng)的核心都離不開(kāi)最簡(jiǎn)單的數(shù)據(jù)訪(fǎng)問(wèn)方法,就是掃描表中的所有行。 PostgreSQL 通過(guò)順序掃描(Sequential Scan)來(lái)實(shí)現(xiàn)這一點(diǎn),它逐行讀取表中的每一行。 雖然對(duì)于大型數(shù)據(jù)集而言,這看起來(lái)可能效率不高,但在特定場(chǎng)景下,它往往是最實(shí)際的選擇。 當(dāng)處理小型表時(shí),使用索引的開(kāi)銷(xiāo)通常超過(guò)其帶來(lái)的好處,因此順序掃描非常有效。 此外,當(dāng)查詢(xún)需要表中大量行時(shí),例如需要查詢(xún)超過(guò)50%的數(shù)據(jù)行時(shí)候,順序掃描可以通過(guò)最小化隨機(jī)I/O來(lái)優(yōu)于索引掃描。 SQL Server采用了一種類(lèi)似的技術(shù),稱(chēng)為表掃描(Table Scan),它逐行讀取整個(gè)表。無(wú)論是PostgreSQL還是SQL Server都依賴(lài)其查詢(xún)優(yōu)化器來(lái)決定何時(shí)應(yīng)選擇表掃描而不是使用索引掃描。例如,在沒(méi)有合適索引的情況下,或者查詢(xún)涉及廣泛的過(guò)濾條件時(shí),優(yōu)化器將選擇全表掃描。盡管順序掃描和表掃描有時(shí)被批評(píng)為較慢,但它們依然是數(shù)據(jù)庫(kù)處理特定工作負(fù)載時(shí)必不可少的工具。 在PostgreSQL中,所有的表默認(rèn)存儲(chǔ)在堆結(jié)構(gòu)(Heap)中,這意味著行沒(méi)有固定的順序。PostgreSQL中沒(méi)有聚集索引的概念,這意味著順序掃描通常會(huì)訪(fǎng)問(wèn)以任意順序存儲(chǔ)的行。
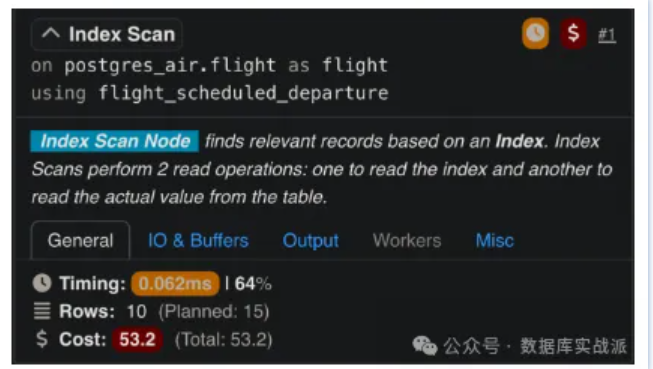
索引掃描在PostgreSQL中,索引掃描(Index Scan)是一個(gè)基本的查詢(xún)執(zhí)行方法,它使用索引來(lái)高效地檢索符合特定查詢(xún)條件的行。 當(dāng)執(zhí)行索引掃描時(shí),PostgreSQL會(huì)遍歷索引結(jié)構(gòu)(B樹(shù))來(lái)查找滿(mǎn)足查詢(xún)條件的行的位置(元組指針)。這些指針將引導(dǎo)PostgreSQL定位到堆表中的相應(yīng)行,進(jìn)而檢索完整的行數(shù)據(jù)。 在PostgreSQL中,索引掃描的關(guān)鍵之處在于,它對(duì)堆表的查找操作是作為索引掃描的一部分內(nèi)部執(zhí)行的。因此,PostgreSQL 執(zhí)行計(jì)劃將索引掃描顯示為一個(gè)單獨(dú)的操作,它封裝了索引遍歷和隨后從堆表中檢索行數(shù)據(jù)這兩個(gè)步驟。 與此不同,SQL Server的執(zhí)行計(jì)劃明確區(qū)分了這兩個(gè)步驟。在SQL Server中,索引查找(Index Seek)操作負(fù)責(zé)遍歷索引以找到匹配的行。當(dāng)索引不包含查詢(xún)所需的所有列時(shí),SQL Server會(huì)引入一個(gè)單獨(dú)的操作,對(duì)于聚集索引表是鍵查找(Key Lookup),對(duì)于堆表則是RID查找(RID Lookup)。這些查找操作會(huì)直接從基礎(chǔ)表中獲取額外的列。通過(guò)分離這些步驟,SQL Server的執(zhí)行計(jì)劃提供了一個(gè)更加清晰詳細(xì)的視圖,展示查詢(xún)?nèi)绾卧L(fǎng)問(wèn)數(shù)據(jù),包括索引遍歷和數(shù)據(jù)行檢索的成本和行為。 這種執(zhí)行計(jì)劃表示的差異凸顯了不同的設(shè)計(jì)理念。 PostgreSQL將堆查找集成到索引掃描操作中,呈現(xiàn)一個(gè)簡(jiǎn)化的執(zhí)行計(jì)劃。然而,這也可能掩蓋索引掃描中堆訪(fǎng)問(wèn)部分的具體成本。另一方面,SQL Server明確分離提供了對(duì)查詢(xún)執(zhí)行過(guò)程更為詳細(xì)的洞察。例如,當(dāng)SQL Server的執(zhí)行計(jì)劃中包含鍵查找時(shí),立刻可以看出索引缺少一些必需的列,這可以幫助數(shù)據(jù)庫(kù)管理員通過(guò)創(chuàng)建覆蓋索引來(lái)消除查找操作。這種透明度對(duì)于識(shí)別和解決復(fù)雜查詢(xún)中的性能瓶頸特別有幫助。
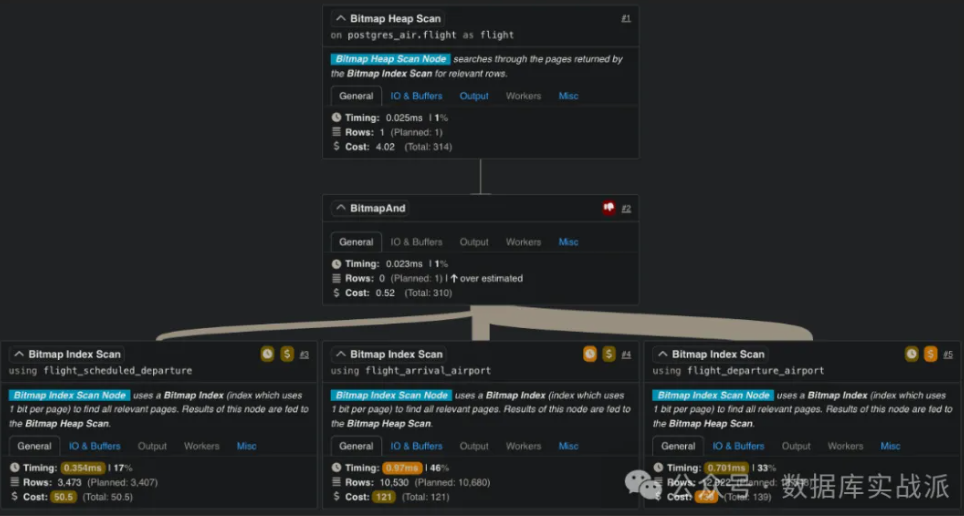
位圖索引掃描與位圖堆掃描對(duì)于具有多個(gè)條件或過(guò)濾器的查詢(xún),PostgreSQL經(jīng)常使用位圖堆掃描(Bitmap Heap Scan),這是一種將索引訪(fǎng)問(wèn)的精確性與批量讀取的高效性相結(jié)合的混合方法。 在執(zhí)行此類(lèi)查詢(xún)時(shí),PostgreSQL首先使用相關(guān)的索引構(gòu)建一個(gè)位圖,即匹配查詢(xún)條件的行的壓縮表示。與逐行訪(fǎng)問(wèn)不同,位圖使PostgreSQL能夠批量獲取這些行從而減少隨機(jī)磁盤(pán) I/O。這種方法對(duì)于必須同時(shí)評(píng)估多個(gè)條件的大型表特別有用,例如按客戶(hù)年齡和地點(diǎn)進(jìn)行過(guò)濾。位圖掃描Bitmap Scan也分為兩個(gè)階段,第一個(gè)階段是Bitmap Index Scan,第二個(gè)階段是Bitmap Heap Scan。Bitmap Heap Scan采用Bitmap Index Scan生成的bitmap(或者經(jīng)過(guò) BitmapAnd 和 BitmapOr 節(jié)點(diǎn)通過(guò)一系列位圖集操作后,生成的bitmap)來(lái)查找相關(guān)數(shù)據(jù)。位圖的每個(gè)page可以是精確的(直接指向tuple的)或有損的(指向包含至少一行與查詢(xún)匹配的page)。 SQL Server并沒(méi)有直接等同于位圖堆掃描的操作,但它在并行查詢(xún)執(zhí)行計(jì)劃中使用位圖過(guò)濾(Bitmap Filtering)。位圖堆掃描在處理需要多個(gè)索引掃描的查詢(xún)時(shí)尤其具有優(yōu)勢(shì),因?yàn)樗鼘⑦@些操作合并為一個(gè)更高效的過(guò)程。這種方法突顯了 PostgreSQL 在動(dòng)態(tài)優(yōu)化復(fù)雜查詢(xún)方面的獨(dú)特能力。通過(guò)平衡順序訪(fǎng)問(wèn)和索引訪(fǎng)問(wèn)的優(yōu)點(diǎn),位圖堆掃描架起了精確性與高效性之間的橋梁,使其在分析和報(bào)告工作負(fù)載中變得不可或缺。
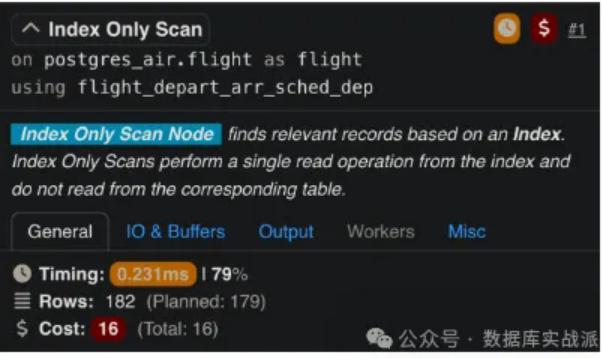
僅索引掃描在PostgreSQL中,僅索引掃描(Index-Only Scans)是一種查詢(xún)執(zhí)行特性,允許數(shù)據(jù)完全從索引中檢索,跳過(guò)對(duì)堆表的訪(fǎng)問(wèn)。 當(dāng)查詢(xún)只涉及索引中的列時(shí),這種方法是可行的。在進(jìn)行僅索引掃描時(shí),PostgreSQL直接從索引的葉節(jié)點(diǎn)中獲取數(shù)據(jù),從而顯著減少了I/O操作并提高了查詢(xún)性能,特別適用于讀密集型工作負(fù)載。例如,如果一個(gè)查詢(xún)僅檢索客戶(hù)的姓名和電子郵件,并且這些列是索引的一部分,那么數(shù)據(jù)庫(kù)完全避免了訪(fǎng)問(wèn)堆表的開(kāi)銷(xiāo)。在SQL Server中,類(lèi)似的概念是通過(guò)覆蓋索引(Covering Indexes)來(lái)實(shí)現(xiàn)的,在索引定義中包含了額外的列(超出索引鍵列的部分)。這些額外的列被稱(chēng)為包含列(Included Columns),它們?cè)试S SQL Server 直接從索引中檢索所有所需的數(shù)據(jù),而無(wú)需執(zhí)行鍵查找(Key Lookup)或 RID 查找(RID Lookup)。
并行查詢(xún)執(zhí)行隨著數(shù)據(jù)集的增大和查詢(xún)變得更加復(fù)雜,采用并行處理對(duì)于保持性能至關(guān)重要。 PostgreSQL支持并行查詢(xún)執(zhí)行,允許多個(gè)工作進(jìn)程分擔(dān)和處理大規(guī)模的工作負(fù)載。例如,并行掃描將一個(gè)大型表分成多個(gè)分段,每個(gè)工作進(jìn)程同時(shí)掃描其中的一部分。這種方法能夠顯著減少資源密集型操作的查詢(xún)時(shí)間。SQL Server也支持執(zhí)行計(jì)劃中的并行處理,使用并行掃描(Parallel Scan)和合并流(Gather Streams)等操作符,將工作負(fù)載分配并合并到多個(gè)工作線(xiàn)程中。SQL Server的并行查詢(xún)引擎與其優(yōu)化器緊密集成,通常能為事務(wù)型OLTP和分析型OLAP工作負(fù)載生成高效的執(zhí)行計(jì)劃。
聚集索引的作用PostgreSQL和SQL Server之間最顯著的區(qū)別之一是PostgreSQL不支持聚集索引。 在SQL Server中,聚集索引定義了表中行的物理順序。這可以顯著提高范圍查詢(xún)或返回按排序順序排列行的查詢(xún)的性能,因?yàn)閿?shù)據(jù)已經(jīng)根據(jù)索引鍵物理排序。 在PostgreSQL中,所有表都以堆(heap)形式存儲(chǔ),這意味著行沒(méi)有特定的存儲(chǔ)順序。雖然PostgreSQL提供了一個(gè)名為CLUSTER的命令,可以基于索引物理重新排序表,但這個(gè)操作不是動(dòng)態(tài)的,必須手動(dòng)執(zhí)行。此外,CLUSTER創(chuàng)建的排序不會(huì)隨著行的插入、更新或刪除而保持。 PostgreSQL的這種設(shè)計(jì)選擇優(yōu)先考慮靈活性,而不是聚集索引可能帶來(lái)的性能提升。 通過(guò)保持表的無(wú)序,PostgreSQL 允許多個(gè)索引并存,這對(duì)于大量數(shù)據(jù)寫(xiě)入的場(chǎng)景或者說(shuō)寫(xiě)多讀少的場(chǎng)景非常有利。
總結(jié)PostgreSQL 和 SQL Server 中的數(shù)據(jù)訪(fǎng)問(wèn)方法展示了各自系統(tǒng)的優(yōu)勢(shì)和優(yōu)先事項(xiàng)。PostgreSQL 的靈活性,例如位圖堆掃描、僅索引掃描,使其成為開(kāi)發(fā)者在查詢(xún)執(zhí)行上尋求精確控制的強(qiáng)大選擇。 然而,PostgreSQL 不支持聚集索引是其與 SQL Server 的一個(gè)關(guān)鍵區(qū)別。另一方面,SQL Server 使用聚集索引來(lái)提供表行的物理排序,這可以顯著有利于范圍查詢(xún)和排序操作。 這種結(jié)構(gòu)性差異體現(xiàn)了兩個(gè)系統(tǒng)的不同哲學(xué):PostgreSQL 傾向于適應(yīng)性,而 SQL Server 強(qiáng)調(diào)緊密集成的優(yōu)化。理解這些差異能夠幫助數(shù)據(jù)庫(kù)專(zhuān)業(yè)人員做出明智的決策,并針對(duì)每個(gè)平臺(tái)的獨(dú)特優(yōu)勢(shì)優(yōu)化查詢(xún)。 ?轉(zhuǎn)自https://www.cnblogs.com/lyhabc/p/18692856/ 該文章在 2025/6/3 10:16:03 編輯過(guò) |
關(guān)鍵字查詢(xún)
相關(guān)文章
正在查詢(xún)... 晴ERP是一款針對(duì)中小制造業(yè)的專(zhuān)業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車(chē)隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類(lèi)企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷(xiāo)售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶(hù)的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")