DuckDB 是一款 嵌入式OLAP數(shù)據(jù)庫(kù) ,專為高效分析型查詢?cè)O(shè)計(jì),被譽(yù)為“分析型SQLite”。它由荷蘭CWI數(shù)據(jù)庫(kù)團(tuán)隊(duì)開(kāi)發(fā),采用MIT開(kāi)源協(xié)議,每月下載量超170萬(wàn)次,GitHub星標(biāo)數(shù)達(dá)29.6k,增速與Snowflake相當(dāng),被DB-Engines預(yù)測(cè)為下一代主流分析引擎。
與傳統(tǒng)行式數(shù)據(jù)庫(kù)(如SQLite)不同,DuckDB采用 列式存儲(chǔ) 和 向量化查詢引擎 ,顯著提升聚合計(jì)算、復(fù)雜過(guò)濾等分析任務(wù)的性能。它無(wú)需獨(dú)立服務(wù)器,僅通過(guò)一個(gè)二進(jìn)制文件嵌入應(yīng)用,支持Python、R、Java等語(yǔ)言,5分鐘即可上手。
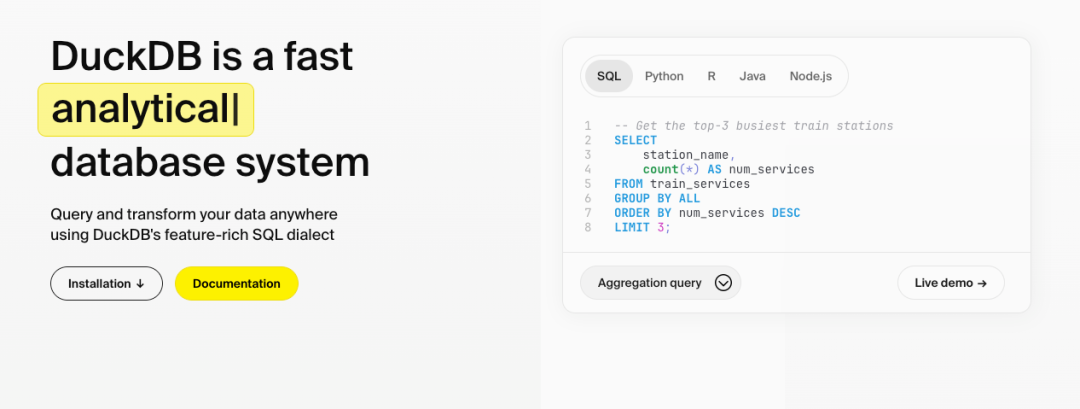
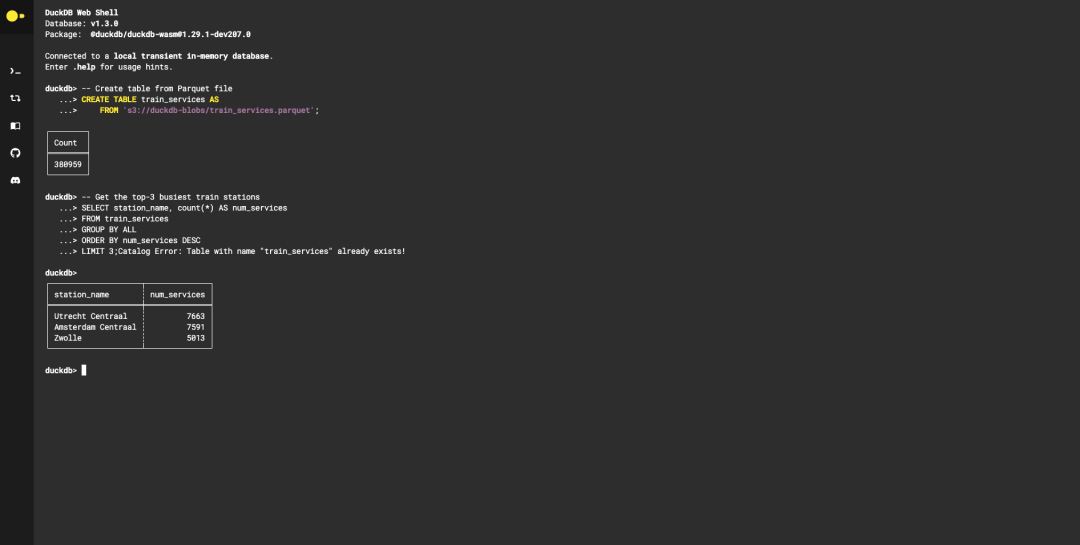
核心功能 一行命令安裝: # macOS brew install duckdb # Python pip install duckdb 支持直接運(yùn)行于瀏覽器(WebAssembly),無(wú)外部依賴。 無(wú)縫集成數(shù)據(jù)科學(xué)生態(tài)
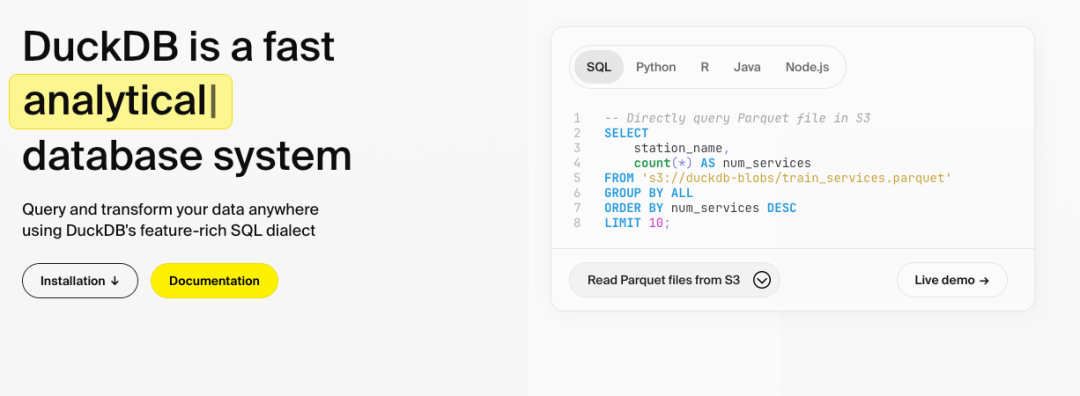
Pandas零拷貝交互 :直接查詢DataFrame,避免內(nèi)存重復(fù)復(fù)制: import duckdb df = pd.read_csv( "data.csv" ) result = duckdb.sql( "SELECT * FROM df WHERE salary > 50000" ).df() 多格式直讀 :直接查詢CSV、JSON、Parquet文件,無(wú)需預(yù)加載: -- 查詢遠(yuǎn)程Parquet文件 SELECT * FROM 's3://bucket/data.parquet' ; 分析優(yōu)化SQL語(yǔ)法 簡(jiǎn)化復(fù)雜查詢,提升可讀性:
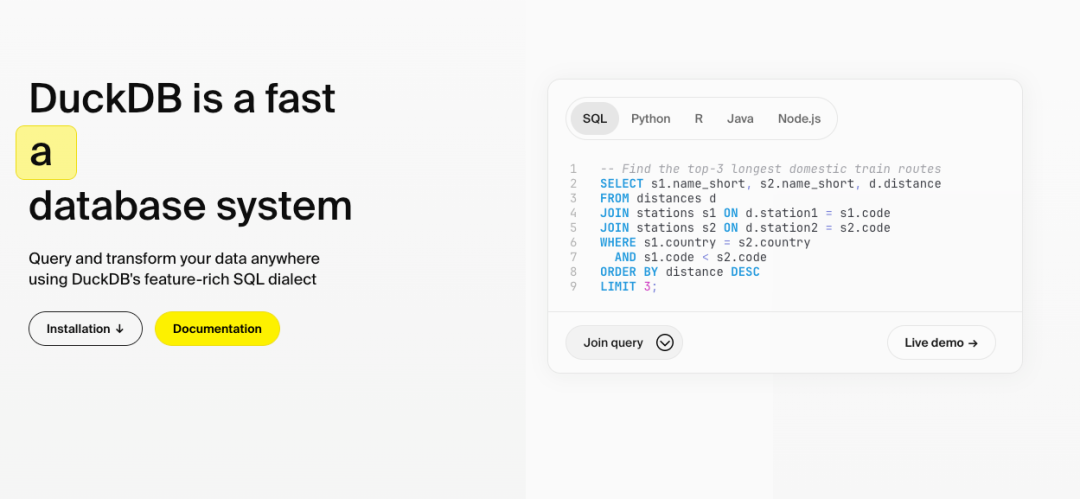
GROUP BY ALL :自動(dòng)按所有非聚合字段分組,避免重復(fù)列名。 SELECT * EXCLUDE :排除指定字段,替代手動(dòng)枚舉: -- 排除email字段 SELECT * EXCLUDE (email) FROM customers; ASOF JOIN :高效連接“接近”的時(shí)間戳數(shù)據(jù),替代復(fù)雜分桶邏輯。 超越內(nèi)存限制的大數(shù)據(jù)處理 通過(guò)輕量壓縮和智能溢出機(jī)制,即使數(shù)據(jù)量超過(guò)內(nèi)存(如100GB),也能利用磁盤(pán)高效完成分析,成本僅為云方案的1/10。
混合云查詢(MotherDuck) 結(jié)合本地與云端數(shù)據(jù)執(zhí)行混合查詢,無(wú)需修改SQL:
ATTACH 'md:' AS motherduck; -- 連接云服務(wù) SELECT local_data.*, cloud_data.* FROM local_table local_data JOIN motherduck.main.cloud_table cloud_data USING ( id ); ?? 行動(dòng)建議 :
# 1. 安裝Python庫(kù) pip install duckdb # 2. 試跑示例 duckdb.sql( "SELECT 'Hello, DuckDB!'" ) 用一行SQL開(kāi)啟你的高效分析之旅!
技術(shù)架構(gòu) 組件 技術(shù)方案 優(yōu)勢(shì) 列式存儲(chǔ) + 輕量壓縮(DataBlocks) 面向讀取優(yōu)化,每列帶min/max索引加速過(guò)濾 批量處理數(shù)據(jù),利用SIMD指令加速計(jì)算 原生嵌套結(jié)構(gòu)(Struct/Map) 直接處理JSON、地理坐標(biāo)等復(fù)雜數(shù)據(jù)
?? 關(guān)鍵創(chuàng)新 :
向量化引擎 :以批處理單元(Vector)流轉(zhuǎn)數(shù)據(jù),減少函數(shù)調(diào)用開(kāi)銷; 字符串優(yōu)化 :短字符串內(nèi)聯(lián)存儲(chǔ),長(zhǎng)字符串保留4字節(jié)前綴加速比較; 無(wú)JIT依賴 :放棄LLVM編譯,保障跨平臺(tái)可移植性。 典型應(yīng)用場(chǎng)景與案例 場(chǎng)景1:探索性數(shù)據(jù)分析(EDA) 問(wèn)題 :Pandas處理10GB以上數(shù)據(jù)緩慢,內(nèi)存不足。 方案 :用DuckDB替代聚合計(jì)算層:
# 從CSV加載1億行數(shù)據(jù) duckdb.sql( """ SELECT genre, AVG(rating) AS avg_rating FROM 'ratings.csv' GROUP BY ALL ORDER BY avg_rating DESC LIMIT 10; """ ).show() 效果 :速度提升5倍,內(nèi)存占用降低60%。
場(chǎng)景2:數(shù)據(jù)湖ETL流水線 架構(gòu) :青銅層(原始數(shù)據(jù))→ 白銀層(清洗)→ 黃金層(聚合)。 DuckDB角色 :在白銀層清洗JSON數(shù)據(jù)并序列化為Parquet:
# 從S3讀取原始JSON,清洗后寫(xiě)回 duckdb.sql( """ COPY ( SELECT id, event_time, user_id FROM read_json('s3://bronze/events.json') WHERE user_id IS NOT NULL ) TO 's3://silver/events.parquet' (FORMAT PARQUET); """ ) 場(chǎng)景3:邊緣設(shè)備實(shí)時(shí)分析 優(yōu)勢(shì) :?jiǎn)挝募渴穑?lt;50MB),適應(yīng)硬件差異,防數(shù)據(jù)損壞。 案例 :工廠設(shè)備傳感器數(shù)據(jù)實(shí)時(shí)聚合,延遲<100ms。
同類產(chǎn)品對(duì)比
語(yǔ)法事例
結(jié)論 替代Pandas/本地ClickHouse :DuckDB在10–100GB單機(jī)分析中性能領(lǐng)先; 補(bǔ)充云數(shù)倉(cāng) :MotherDuck實(shí)現(xiàn)混合查詢,降低云端數(shù)據(jù)傳輸成本。 數(shù)據(jù)科學(xué)家 :替代Pandas處理中大型數(shù)據(jù)集,復(fù)用SQL技能; 嵌入式應(yīng)用開(kāi)發(fā)者 :需內(nèi)置高性能分析功能的設(shè)備端應(yīng)用; 數(shù)據(jù)工程師 :作為輕量級(jí)ETL引擎,橋接本地與云端數(shù)據(jù)流。 項(xiàng)目地址 https://github.com/duckdb/duckdb
閱讀原文:原文鏈接
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")