一張表到底建多少個索引才是合適呢?
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
上周的一天,到公司接了杯水剛剛坐穩,就看到 DBA就在群里@ 某個研發帥哥,說“你的表已經有10個索引了,怎么這次還要再加呢?”
那我就在想:一張表到底建多少個索引才是合適呢? 要搞懂這個問題,我們就需要弄清楚以下這幾個問題: 1)常見的索引分類有哪些? 2)MySQL 是如何使用索引的? 3)一張表最多可以建多少索引? 4)新建索引的規范原則有哪些? 本文我們就一起來展開聊聊這幾個問題~  ?1、常見的索引分類有哪些?1.1 應用層分類從應用層面,常見分類:
1.2 數據結構層分類從數據結構層面,分類如下:
2、新建索引的規范原則有哪些?關于新建索引,通常需要注意以下規范原則: 2.1 最左前綴匹配原則MySQL 會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配
2.2 盡量選擇區分度高的列作為索引區分度的公式是:count(distinct col)/count(*),表示字段不重復的比例,比例越大我們掃描的記錄數越少。 唯一鍵的區分度是1,而一些 status 狀態、性別等 字段可能在大數據面前區分度就是0。 2.3 索引列不能參與計算保持索引列“干凈”,這個原因其實很簡單,b+樹中存的都是數據表中的字段值。但是在進行檢索時,需要把所有元素都應用函數才能比較,顯然成本太大。
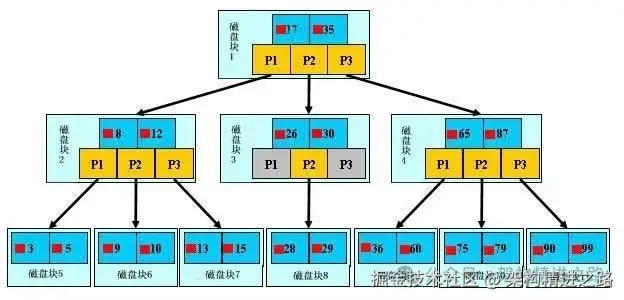
2.4 盡量的擴展索引,不要新建索引比如表中已經有a的索引,現在要加(a,b)的索引,那么只需要修改原來的索引即可,而不建議再單獨去建一個b索引。 3、MySQL 是如何使用索引的?索引用于快速查找具有特定列值的行,其目的在于提高查詢效率。 與我們查閱圖書所用的目錄是一個道理:先定位到章,然后定位到該章下的一個小節,然后找到頁數。相似的例子還有:查字典,查火車車次,飛機航班等。 本質都是:通過不斷地縮小想要獲取數據的范圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件。 也就是說,有了這種索引機制,我們可以總是用同一種查找方式來鎖定數據。 數據庫也是一樣,但顯然要復雜得多,因為不僅面臨著等值查詢,還有范圍查詢(>、<、between、in)、模糊查詢(like)、并集查詢(or)等等。數據庫應該選擇怎么樣的方式來應對所有的問題呢? 大多數 MySQL 索引(PRIMARY KEY、UNIQUEINDEX 和FULLTEXT)都存儲在 B樹 中。
在 MySQL 中,使用索引進行以下操作: 3.1 = 和 in 可以亂序比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,MySQL 的查詢優化器會幫你優化成索引可以識別的形式。 3.2 and 與 or聯合索引:(d,a,b,c)
MySQL 會按照聯合索引,從左到右的順序找一個區分度高的索引字段(這樣便可以快速鎖定很小的范圍),加速查詢,即按照d—>a->b->c的順序
MySQL 會按照條件的順序,從左到右依次判斷,即a->b->c->d 4、一張表最多可以建多少個索引?4.1 理論上來說MySQL 的存儲引擎(如 InnoDB、MyISAM 等)本身并沒有對一個表能創建的索引數量設置一個固定數值限制,,而是由MySQL數據庫引擎內部的數據結構和算法決定的。 從數據庫設計和架構的角度,理論上只要滿足以下條件,就可以新增創建索引:
4.2 實際應用情況然而在實際應用場景中,通常不會無限制地創建索引。一方面是因為上述提到的性能問題,過多的索引往往會導致數據更新操作變得極為緩慢,嚴重影響系統的正常運行。
另一方面,不同的 MySQL 版本以及不同的存儲引擎在實際表現上也會有差異。
總結索引是應用程序設計和開發的一個重要方面。若索引太多,應用程序的性能可能會受到影響。而索引太少,對查詢性能又會產生影響,要找到一個平衡點,這對應用程序的性能至關重要。 MySQL 表能創建的索引數量沒有一個確切的、通用的絕對上限,而是要綜合考慮多方面因素,在滿足性能要求和存儲空間允許的條件下合理創建索引。 其實做了這么長時間的語句優化后才發現,任何數據庫層面的優化都抵不上應用系統的優化,同樣是MySQL,可以用來支撐Google/FaceBook/Taobao應用,但可能連你的個人網站都撐不住。套用最近比較流行的話:“查詢容易,優化不易,且寫且珍惜!” 轉自https://juejin.cn/post/7433575991878451200 該文章在 2025/4/14 10:45:43 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886